前馈神经网络(feedforward neural network)也被称作深度前馈网络(deep feedforward network)或多层感知器(multilayer perceptron, MLP),是典型的深度学习模型。前馈网络的目标是近似某个函数$f^{\star}$,这个$f^{\star}$完成特定的分类或者回归功能。
线性分类和线性回归问题,考虑的是固定的基函数的线性组合模型。这一些模型具有一定的分析性质和计算性质。对于高维问题,它们的实际应用常常被限制。为了使得这些模型处理大规模数据,有必要根据数据来调节基函数。
固定基函数的数量,但是允许基函数是可调的,即使用参数形式的基函数,这些基函数可以在训练阶段调节。在模式识别中,这种类型的最成功的的模型是前馈神经网络,也被称为多层感知器(multilayer perceptron, MLP)。对于许多应用来说,与具有同样泛化(generalization)能力的支持向量机(support vector machine, SVM)相比,多层感知器的模型会相对简洁,因此计算速度更快。这种简洁性带来的代价是,与相关向量机(relevant vector machine, RVM)一样,构成网络训练根基的似然函数不再是模型参数的凸函数。
感知机模型
M-P神经元模型
神经网络中最基本的成分是神经元(neuron)模型,McCulloch和Pitts将神经元抽象为图-1所示模型,这就是一直沿用至今的“M-P神经元模型”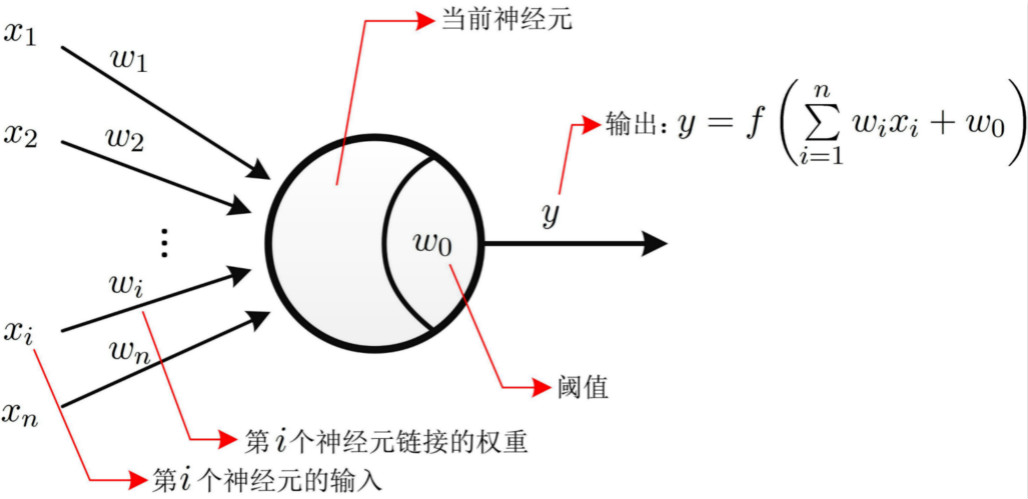
在这个M-P神经元模型中,当前神经元接收到$n$个神经元传递的信号$\left\{x_1,\cdots,x_n\right\}$,这些信号通过带权重$\left\{w_1,\cdots,w_n\right\}$的链接进行传递。神经元的总输入将与神经元的阈值$\theta$进行比较,然后再通过“激活函数”(activation function )处理产生神经元输出。
感知机是由两层神经元组成,其中输入层的作用是接收外界信号并传递给输出层,输出层神经元进行激活函数处理,因此,感知机只拥有一层功能神经元。感知机能完成简单的逻辑“与”、“或”、“非”运算,我们通过图-2的例子进行介绍。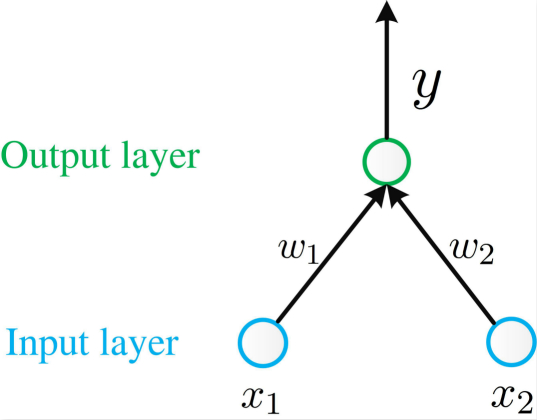
其中$f(\cdot)$为阶跃函数
- “与”: 令$w_1=w_2=1$,$w_0=-2$,则$y=f(x_1+x_2-2)$,仅仅当$x_1=x_2=1$时候,$y=1$。
- “或”: 令$w_1=2_2=1$,$2_0=-0.5$,则$y=f(x_1+x_2-0.5)$,当$x_1=1$或$x_2=1$时,$y=1$。
- “非”: 令$w_1=-0.6$,$w_2=0$,$w_0=0.5$,则$y=f(-0.6x_1+0.5)$,当$x_1=1$时,$y=0$,当$x_1=0$时,$y=1$。同理也可以设置为非$x_2$。
Remakrs: 感知机主要用于处理线性可分的二分类问题。对于多分类以及非线性可分问题,需要考虑使用多层神经元。
前馈神经网络
为了扩展感知机的处理范围,通过增加隐含层(hidden layer),构成多层感知机(multilayer perceptron),用于处理多分类以及非线性可分问题。多层感知机也称前馈神经网络。前馈神经网络有如下特点
- 每一层的神经元与下一层神经元完全互连;
- 同层神经元不存在相互连接;
- 不存在跨层连接;
这里,我们通过如图-3所示的单隐含层来介绍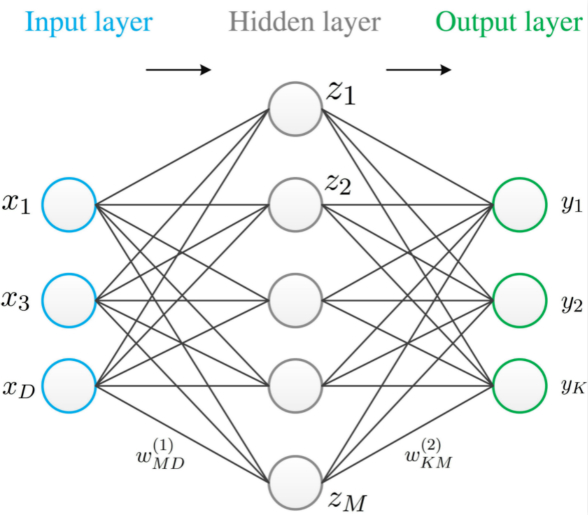
隐藏层第$j$个神经元的输入(激活)为
\begin{align}
a_j=\sum_{i=1}^Dw_{ji}^{(1)}x_i+w_{j0}^{(1)}
\end{align}
其中,我们用上标来表示第一“层”权重,注意这里的“层”和神经元的层数相区别。$w_{j0}$表示偏置(basis)。每一个激活都使用一个可微的非线性激活函数(activation function)$f(\cdot)$进行变换,可以得到隐藏层第$j$个神经元的输出
\begin{align}
z_j=f(a_j)
\end{align}
同理,输出层第$k$个神经元的输入(激活)和输出分别为
\begin{align}
a_k&=\sum_{j=1}^M w_{kj}^{(2)}z_j+w_{k0}^{(2)}\\
y_k&=f(a_k)
\end{align}
注意,这里激活函数可以是不一样的。
- 对于标准的回归问题,这里的激活函数就是一个恒等函数,即$y_k=a_k$。
- 对于多元二分类问题,则每个输出单元激活函数使用logistic sigmoid函数,即$y_k=\sigma(a_k)$。
对于多元二分类问题,我们整合各个阶段,得到
\begin{align}
y_k(\boldsymbol{x},\boldsymbol{w})=\sigma \left[\sum_{j=1}^M w_{kj}^{(2)}f\left(\sum_{i=1}^Dw_{ji}^{(1)}x_i+w_{j0}^{(1)}\right)+w_{k0}^{(2)}\right]
\end{align}
因此,神经网络可以简单看成是输入$\boldsymbol{x}$与输出$\boldsymbol{y}$的非线性函数,并且可以通过调整权值$\boldsymbol{w}$控制。前馈神经网络是感知机的组合,所不同的是,前馈神经网络所用的激活函数是一个可微函数,而感知机使用的是阶跃函数,阶跃函数存在不可导点。
网络训练
我们把神经网络看成从输入向量$\boldsymbol{x}$到输出向量$\boldsymbol{y}$的非线性函数。为此,我们需要确定网络的参数。给定训练集$\mathcal{S}=\left\{\boldsymbol{x}_n,\boldsymbol{t}_n\right\}_{n=1}^N$,参数的确定可以通过最小平方误差函数(最小二乘)得到
\begin{align}
E(\boldsymbol{w})=\frac{1}{2}\sum_{n=1}^N||\boldsymbol{y}(\boldsymbol{x}_n,\boldsymbol{w})-\boldsymbol{t}_n||^2
\end{align}
更一般地,我们从概率的角度出发,给网络的输出提供一个概率形式的表示(即描述输出的可能性)。
回归问题
回归问题相对于分类问题容易理解,我们首先讨论回归问题。这里,我们只考虑一元目标变量$t$的情况,其中$t$可以取任何实数。我们假定$t$服从高斯分布
\begin{align}
p(t|\boldsymbol{x},\boldsymbol{w})=\mathcal{N}(t|y(\boldsymbol{x},\boldsymbol{w}),\beta^{-1})
\end{align}
给定训练集$\mathcal{S}=\left\{\boldsymbol{x}_n,t_n\right\}_{n=1}^N$,我们可以构造对应的似然函数
\begin{align}
p(\boldsymbol{t}|\boldsymbol{X},\boldsymbol{w},\beta)=\prod_{n=1}^N \mathcal{N}(t_n|y(\boldsymbol{x}_n,\boldsymbol{w}),\beta)
\end{align}
取负对数,有
\begin{align}
J=\frac{\beta}{2}\sum_{n=1}^N\left[y(\boldsymbol{x}_n,\boldsymbol{w})-t_n\right]^2-\frac{N}{2}\ln \beta+\frac{N}{2}\ln 2\pi
\end{align}
因此,求解参数$\boldsymbol{w}$,最大似然函数法与最小二乘等价。即
\begin{align}
\boldsymbol{w}_{\text{ML} }=\underset{\boldsymbol{w} }{\arg \min}\frac{1}{2}\sum_{n=1}^N\left[y(\boldsymbol{x}_n,\boldsymbol{w})-t_n\right]^2
\end{align}
在实际应用中,由于$y(\boldsymbol{x}_n,\boldsymbol{w})$的非凸性,因此寻找到的$\boldsymbol{w}$通常是似然函数的局部最优,而非全局最优。
在已经找到$\boldsymbol{w}_{\text{ML} }$的情况下,通过最小化似然函数求$\beta$,得到
\begin{align}
\beta_{\text{ML} }^{-1}=\frac{1}{N}\sum_{n=1}^N\left[y(\boldsymbol{x}_n,\boldsymbol{w})-t_n\right]^2
\end{align}
很明显,$\beta_{\text{ML} }$的值依赖$\boldsymbol{w}_{\text{ML} }$。一旦参数$\boldsymbol{w}_{\text{ML} }$找到,相应地$\beta_{\text{ML} }$也可以被计算出来。
若目标变量为多个,则假设目标变量之间相互独立,且噪声精度均为$\beta$,即
\begin{align}
p(\boldsymbol{t}|\boldsymbol{x},\boldsymbol{w})=\mathcal{N}(\boldsymbol{t}|y(\boldsymbol{x},\boldsymbol{w}),\beta^{-1}\mathbf{I})
\end{align}
分类问题
我们从最简单的一元二分类问题开始。假设单一目标变量$t$,$t=1$表示类别$\mathcal{C}_1$,$t=0$表示类$\mathcal{C}_2$,我们考虑一个具有单一输出的网络,它的激活函数为logistic sigmoid函数
\begin{align}
y=\sigma(a)=\frac{1}{1+\exp (-a)}
\end{align}
从而$0<y(\boldsymbol{x},\boldsymbol{w})<1$,我们把$y(\boldsymbol{x},\boldsymbol{w})$看成是给定$\boldsymbol{x}$输入$\mathcal{C}_1$的概率,即$y(\boldsymbol{x},\boldsymbol{w})=p(\mathcal{C}_1|\boldsymbol{x})$,则$p(\mathcal{C}_2|\boldsymbol{x})=1-y(\boldsymbol{x},\boldsymbol{w})$。如果给定输入,那么目标变量的条件概率分布是一个伯努利分布,形式为
\begin{align}
p(t|\boldsymbol{x},\boldsymbol{w})=y(\boldsymbol{x},\boldsymbol{w})^t[1-y(\boldsymbol{x},\boldsymbol{w})]^{1-t}
\end{align}
如果我们考虑一个由独立的观测量组成的训练集,那么由负对数似然函数给出的误差函数就是一个交叉熵(cross entropy)误差函数,形式为
\begin{align}
E(\boldsymbol{w})=-\sum_{n=1}^N\left[t_n \ln y_n+(1-t_n)\ln(1-y_n)\right]
\end{align}
其中$y_n$表示$y(\boldsymbol{x}_n,\boldsymbol{w})$。注意,这里没有与噪声精度$\beta$相类似的参数,因为我们假定目标值的标记都是正确。然而,这个模型很容易扩展到能够接受标记错误的情形。Simard等人发现,对于分类问题,使用交叉熵误差函数而不是平方和误差函数,会使训练速度更快,同时提升泛化能力。
对于$K$个二分类问题,对应的,我们可以使用具有$K$个输出的神经网络,每个输出都具有一个logistic sigmoid激活函数。与每个输出相关联的是一个二元类别标签$t_k\in \left\{0,1\right\}$,其中$k=1,\cdots,K$。如果我们假定类别标签是相互独立的,那么给定输入向量,目标向量的条件概率分布为
\begin{align}
p(\boldsymbol{t}|\boldsymbol{x},\boldsymbol{w})=\prod_{k=1}^K y_k(\boldsymbol{x},\boldsymbol{w})^{t_k}\left[1-y_k(\boldsymbol{x},\boldsymbol{w})\right]^{1-t_k}
\end{align}
取似然函数的负对数,得到误差函数
\begin{align}
E(\boldsymbol{w})=-\sum_{n=1}^N\left[t_n\ln y_n+(1-t_n)\ln (1-y_n)\right]
\end{align}
对于多分类问题。我们考虑标准的多分类问题,其中每个输入被分到$K$个互斥的类别中。二元目标变量$t_k\in (0,1)$使用$1-\text{of}-K$表达方式来表示类别,从而网络的输出可以表示为$y_k(\boldsymbol{x},\boldsymbol{w})=p(t_k=1|\boldsymbol{x})$,因此误差函数为
\begin{align}
E(\boldsymbol{w})=-\sum_{n=1}^N\sum_{k=1}^K t_{nk}\ln y_{k}(\boldsymbol{x}_n,\boldsymbol{w})
\end{align}
其中
\begin{align}
y_k(\boldsymbol{x},\boldsymbol{w})=\frac{\exp (a_k)}{\sum_j \exp (a_j(\boldsymbol{x},\boldsymbol{w}))}
\end{align}
Remarks: 神经网络可以完成回归和分类两大任务,其具体区别在于输出层的激活函数。
参数优化
网络的参数优化是寻找使得误差函数$E(\boldsymbol{w})$最小的权向量$\boldsymbol{w}$。从$\boldsymbol{w}_A$点到极值点$\boldsymbol{w}_B$之间存在着无数的路径,其中最快速的方案是,按照梯度的负方向运动(梯度反方向是函数值下降最快的方向,说明梯度方向是函数值上升最快的方向)。当梯度为零时,即$
\nabla E(\boldsymbol{w})=0$,我们称这样的点为驻点。它可以进一步划分为极小值点,极大值点和鞍点。
我们的目标是寻找一个向量$\boldsymbol{w}$使得$E(\boldsymbol{w})$最小。然而,误差函数通常与权值、偏置是高度非线性关系,因此权值空间中会有很多梯度为零的点。即,存在很多局部极小值点(local minimum point)。对于一个成功使用神经网络的应用来说,可能没有必要寻找全局最小值点(golobal minimum point),而是通过比较几个局部极小值,得到最优解。
由于无法找到方程$\nabla E(\boldsymbol{w})=0$的解析解,因此我们使用迭代的数值方法。连续非线性函数的最优化问题是一个被广泛研究的问题,有相当多的文献讨论如何高效地解决此类问题。大多数方法设计到为权向量选择某个初始值$\boldsymbol{w}_0$,然后在权空间中进行一系列移动,形式为
\begin{align}
\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)}+\triangle \boldsymbol{w}^{(t)}
\end{align}
其中$t$为迭代次数。不同的算法所涉及到权向更新$\triangle \boldsymbol{w}^{(t)}$的不同选择。许多算法使用梯度信息,因此就需要在每次更新之后计算在新的权向量$\boldsymbol{w}^{(t+1)}$处的$\triangle E(\boldsymbol{w})$。
局部二次近似
梯度的计算通常比较复杂,通过对误差函数$E(\boldsymbol{w})$进行二次近似,是一种减少计算量的方案
\begin{align}
E(\boldsymbol{w})\approx E(\hat{\boldsymbol{w} })+(\boldsymbol{w}-\hat{\boldsymbol{w} })^T\boldsymbol{b}+\frac{1}{2}(\boldsymbol{w}-\hat{\boldsymbol{w} })^T\boldsymbol{H}(\boldsymbol{w}-\hat{\boldsymbol{w} })
\end{align}
其中
\begin{align}
\boldsymbol{b}&=\nabla E(\boldsymbol{w})|_{\boldsymbol{w}=\hat{\boldsymbol{w} }}\\
(\boldsymbol{H})_{ij}&=\frac{\partial E(\boldsymbol{w})}{\partial w_i\partial w_j}|_{\boldsymbol{w}=\hat{\boldsymbol{w} }}
\end{align}
相对应地,梯度为
\begin{align}
\nabla E(\boldsymbol{w})\approx \boldsymbol{b}+\boldsymbol{H}(\boldsymbol{w}-\hat{\boldsymbol{w} })
\end{align}
随机梯度下降
随机梯度下降的权值更新公式为
\begin{align}
\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)}-\eta \nabla E(\boldsymbol{w}^{(t)})
\end{align}
其中参数$\eta$为学习率(learning rate)。注意,误差函数是关于训练集定义的,因此为了计算$\nabla E$,每一步都需要处理整个数据集。事实上随机梯度下降是一种很差的算法,因为每一次更新权值的时候,都需要遍历一次训练集数据。
梯度下降法中有一个在线的版本,这个版本被证明在实际应用中对于使用大规模数据集来训练神经网络的情形很有用。基于一组独立观测的最大似然函数的误差函数由一个求和公式构成
\begin{align}
E(\boldsymbol{w})=\sum_{n=1}^N E_n(\boldsymbol{w})
\end{align}
在线梯度下降,也称为顺序梯度下降(sequential gradient descent)或者随机梯度下降(stochastic gradient descent),使权向量的更新每次只依赖于一个数据点,即
\begin{align}
\boldsymbol{w}^{(t+1)}=\boldsymbol{w}^{(t)}-\eta\nabla E_n(\boldsymbol{w}^{(t)})
\end{align}
这个更新在数据集上循环重复,并且既可以顺序地处理数据,也可以随机地有重复地选择数据点。当然,也有折中的方法,即每次更新依赖于一部分数据。